Author's Note: This article follows “Speed By A Thousand Cuts” as the second installment of the series.
A majority of the traffic to item pages comes from search results page. (The item page is the page buyers see when they find an item they want to buy.) If we can do any improvements to help the item page speed during or after a search page load, without degrading search performance, it will be a good win for the business and for user experience.
In past years, we prefetched selective item images shown on the item page, after search page is loaded, which helped to minimize throbbers and show item images instantly on item pages.
This time, we used predictive item data prefetch caching, along with user context content, to serve the entire item page for traffic from search results page. Based on business metric values and the additional capacity required for prefetching, usually the top 5 or 10 items in search results are chosen for prefetch caching. These are the items that typically convert better and have a good chance of user clicking on those item URLs.
What is predictive item data prefetch caching: In simple words, for certain search request we intelligently prefetch top item pages and cache it. When user clicks on one of these items from search result, the item page is fetched from cache instantaneously rather than going to downstream services.
Architecture
The architecture of item prefetch caching allows us to prefetch the item pages in the background and store them in the server-side cache. The time taken by the search service and the front-end search page is used to render the search page request to prefetch the cache internally and make it ready.
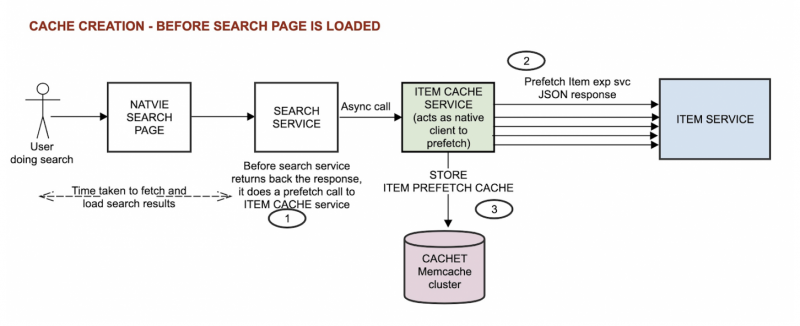
Server-side prefetch caching flow when user does search
Cache creation
When a user performs a search, the request comes to search service to fetch a list of items to be shown. While processing the search results, search service triggers an asynchronous call (1) to item cache service with set of predictive item URLs. Item cache service, in turn, triggers individual prefetch calls (2) to item service. The prefetched item service response data is then stored (3) in a memcache cluster, “CACHET.” Search service then attaches a flag to each prefetched item and returns a response to the client indicating cache eligibility.

Figure 1. Cache creation.
Cache Hit and Miss
When a user clicks on any of the items on the search page, the item page request goes back to item service with a special header indicating this item can be prefetched and cached. Item service then checks for this header and reads (2) the cached item data from the memcache cluster. If a cache is found, it will be returned back to the user to render the item page. In case of a cache miss, item service will fall back (3) to its original dependencies to retrieve the item data from the database and other micro services.

Figure 2. Cache hit or miss.
Cache
Cache Storage Selection
Any caching storage we choose had to meet the below criteria so that we can build a reliable system:
- Insert: Our use case demands millions of insertion per hour to cache.
- Read: Our use case demands under 15 millisecond of SLA with millions of lookups.
- Delete: Should be able to support millions of deletes per hour
- TTL: Should be able to support a TTL from under a minute up to 3 days.
- Scaling: Should be able to scale without compromising any of the above metrics as the data grows from few million or hundreds of millions or the storage grows from few GB to TBs.
Building such a prefetch system can be costly due to the cost for performance and capacity involved. We wanted to stay frugal wherever possible and optimize the system to get the best out of it while minimizing the cost. So any system we choose had to give us performance benefits with minimum investment. We analyzed and defined the below additional parameters to optimize for performance and cost.
- Async Insertions: Inserts have to be async and as fast as possible to reduce resource consumption and save compute cycles on thread wait time.
- Data Persistence: The primary goal of this cache is to optimize speed and return faster responses. Since we have a reliable fallback (a.k.a Item Service) in case of a cache miss or if prefetch wasn’t available, data persistence is secondary here. We don't need persistence because the system can be fail-open.
- Consistency: Since the system is fail-open and we have a fall back, async eventual consistency works for us within an SLA of few hundred milliseconds before the user click happens and the GET request arrives.
- Secondary Replicas in same Data Center: We wanted something without the need of a replica. By comparison, for example, Couchbase needs a replica in each region. That would balloon cost and footprint.
- Availability: There are no replicas to reduce cost within the same data center, because we can still rely on multiple data centers to improve availability.
- Tight SLA: Our SLA is very tight (15 ms). The system should be able to meet this so that there is a minimum impact on speed in case of a cache miss.
To meet all the above criteria for cache storage, we use a lightning fast, low latency, in-memory key-value store solution named CACHET [memcached + mcrouter] cluster, which is fully managed in the cloud and distributed across multiple data centers. A CACHET memcached cluster consists of mcrouter and memcached nodes that are integrated with eBay’s logging and reporting tools. Applications send a request to a mcrouter, which then sends the request to one or more memcached instances based on the defined mcrouter pool routes.

Figure 3. CACHET memcached clusters.
Performance
CACHET is configured to serve millions of requests within an SLA of <10ms. The following statistics show the number of item requests and 95% read latency per minute (average).

Figure 4. Data Centers: lvs - Las Vegas, slc - Salt Lake City, rno - Reno.

Figure 5. r1vicache - Item Cache Service pool.
Data Storage, Retrieval and transmission
For write requests, the payload is zipped before storing into cache to save storage memory.
For read requests, the payload is retrieved from cache in zipped format and transmitted in zipped format back to the application pool to save zipping and unzipping time on cache pool and save time to transmit less number of bytes with zipped data for optimization.
Key Generation
MD5(hex) keys are generated for incoming load and read requests based on {itemid}:{siteid}:{locale}:{userUniqueIdentifier/sessionId}:{userid}:{urlQueryParams}. This makes the cache specific to a particular user. MD5(hex) is used purely to save storage space needed for keys.

Figure 6: The cache hit ratio per minute (average).
Advantages of server-side prefetching
Predictive item prefetch caching using server-side prefetching has many advantages over other techniques.
- The search service can trigger an asynchronous call to the ITEM CACHE service, which does the predictive prefetching of item content. Since this call is asynchronous, there is no notable latency to users in the search experience.
- Since the call to ITEM CACHE is triggered even before search service returns back for browser to render the search page, the whole prefetching and server side caching can complete and will be ready before the user hits the item URL in the search page.
- This is not device dependent and can scale for low-end devices or slow phone networks.
Cache data validation
To ensure consistent user experience with prefetched and cached item content, the state of the item and user is saved along with the cached item content. During cache read, all the below conditions are checked for cached data validity.
- Whether user’s sign in state has changed
- Is the item revised by the seller
- Has the item-to-user relation changed
- Does the user locale or language preference changed
Also certain scenarios where items should not be prefetched are validated. Some of them are listed below.
- Item ending in few mins
- Item already ended
- Item belonging to certain categories
- Complex scenarios with product experience where content is very dynamic
TTL
To minimize the impact of stale data on the page, the TTL of the cache is set to a few mins. This is based on the average time a user spends on the search page and the time taken to requery items on the search page, as shown in the following graph.

Figure 7. The average time a user spends on the search page and the time taken to requery items on the search page.
Speed improvement
When a user accesses the prefetched cached item data, the response time of item service decreases by several milliseconds (~400ms). Since prefetch is done for the top 5-10 items allowing the optimum balance of impact and cost, it covers 70% of search to item page traffic. Taking this ratio into consideration, the overall speed for above the fold rendering time has improved by 10%.
Next steps
This feature is launched in Android and iOS native platforms for U.S. U.K., Germany and Australia markets. A variant of the same server side prefetch caching combined with client side prefetch is launched in desktop platform for Australia market. We are seeing good speed and business wins in all markets. A future improvement of this prefetching architecture is to move the server-side cache to the edge close to the users to save the network latency and bandwidth. Also moving towards a cache which is generic across multiple users (known as non user context cache) using the same prefetch architecture will further reduce the operations cost and improve cache hit efficiency.
Thanks to our leadership Lakshimi Duraivenkatesh and Senthil Padmanabhan for guiding us through out this initiative.