We are happy to announce ql.io – a declarative, evented, data-retrieval and aggregation gateway for HTTP APIs. Through ql.io, we want to help application developers increase engineering clock speed and improve end user experience. ql.io can reduce the number of lines of code required to call multiple HTTP APIs while simultaneously bringing down network latency and bandwidth usage in certain use cases.
ql.io consists of a domain-specific language inspired by SQL and JSON, and a node.js-based runtime to process scripts written in that language. Check out ql.io on Github for the source and http://ql.io for demos, examples, and docs.

Why ql.io
HTTP based APIs – some call them services – are an integral part of eBay’s architecture. This is true not just for eBay, but for most companies that use the Web for content and information delivery. Within eBay’s platform engineering group, we noticed several pain points for application developers attempting to get the data they need from APIs:
- Most use cases require accessing multiple APIs – which involves making several network round trips.
- Often those API requests have interdependencies – which requires programmatic orchestration of HTTP requests – making some requests in parallel and some in sequence to satisfy the dependencies and yet keep the overall latency low.
- APIs are not always consistent as they evolve based on the API producers’ needs – which makes code noisier in order to normalize inconsistencies.
We found that these issues have two critical impacts: engineering clock speed and end user experience.
- Engineering clocks slow down because developers need to account for dependencies between API calls, and to arrange those calls to optimize overall latency. Implementing orchestration logic involves multi-threaded fork-join code, leads to code bloat, and distracts from the main business use case that the developer is striving to support.
- End user experience suffers due to high bandwidth usage as well as the latency caused by the number of requests and the processing overhead of non-optimized responses from APIs.
The goal of ql.io is to ease both pain points:
- By using a SQL- and JSON-inspired DSL to declare API calls, their interdependencies, forks and joins, and projections, you can cut down the number of lines of code from hundreds of lines to a few, and the development time from entire sprints to mere hours. Using this language, you can create new consumer-centric interfaces that are optimized for your application’s requirements.
- You can deploy ql.io as an HTTP gateway between client applications and API servers so that ql.io can process and condense the data to just the fields that the client needs. This helps reduce the number of requests that the client needs to make as well as the amount of data transported to clients.
A quick taste
Here is one of the typical examples of ql.io usage. It shows how ql.io can transform the experience of a developer getting the data needed to paint the UI in a native application.
prodid = select ProductID[0].Value from eBay.FindProducts where
QueryKeywords = 'macbook pro';
details = select * from eBay.ProductDetails where
ProductID in ('{prodid}') and ProductType = 'Reference';
reviews = select * from eBay.ProductReviews where
ProductID in ('{prodid}') and ProductType = 'Reference';
return select d.ProductID[0].Value as id, d.Title as title,
d.ReviewCount as reviewCount, r.ReviewDetails.AverageRating as rating
from details as d, reviews as r
where d.ProductID[0].Value = r.ProductID.Value
via route '/myapi' using method get;
This script uses three API calls (in this case, all offered by eBay) to get four fields of products that match a keyword. The result is provided via a new HTTP resource with URI http://{host}:{port}/myapi. See the guide to build this example yourself, or copy and paste the above script into ql.io’s Web Console to see it in action.
While we are still working on various benchmarks, we want to share some early results on developer productivity and end user benefits. One of the teams at eBay recently migrated an application that relies solely on eBay’s APIs to get the data needed to paint its UI. The first diagram below shows the request-response traces before migrating to ql.io.
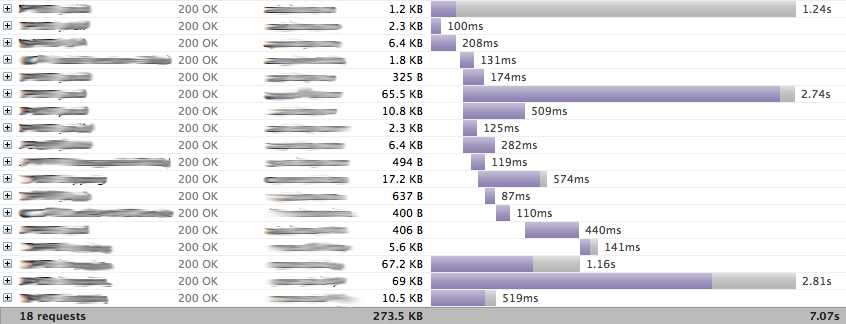
The code related to these API calls was about 2800 lines long. The diagram below shows the request-response traces after migrating API access to ql.io.

This effort brought the code down to about 1200 lines, in addition to reducing the number of requests from 18 to 5 and the data size from 274k to 91k. In this experiment, latency drop is not significant as the client application was using broadband and some of the APIs used were slow APIs.
How to use ql.io
ql.io is not intended to replace frameworks that are currently used to build HTTP APIs. API producers can continue to use existing frameworks to offer interfaces that are generic and broadly reusable. ql.io comes into play when a consumer of APIs wants to implement consumer-specific aggregation, orchestration, and optimizations. In other words, while existing frameworks continue to support “producer-controlled” interfaces, you can use ql.io to create “consumer-controlled” interfaces.
We are building ql.io with flexible deployment in mind. Depending on where the network costs are felt, you can deploy ql.io closer to API servers, closer to users on the edge, or even on front-end machines.
Deploying closer to API servers
The primary usage of ql.io is to run it as a gateway at the reverse proxy tier, potentially between your load balancers and API servers.

Deploying closer to client applications
A secondary usage is to deploy ql.io closer to client applications on the edge.
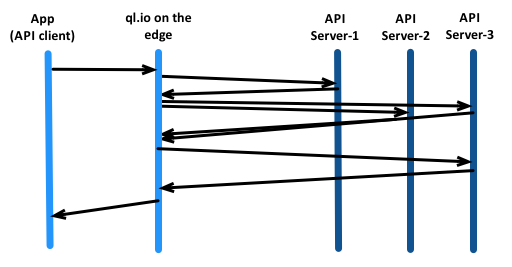
Edge-side deployment can further reduce network costs for client applications by pushing API orchestration closer to those applications. Where API servers are globally distributed and the best place for aggregation may be closer to client applications, edge-side deployment may yield significant gains. If you are a developer using third-party APIs, you can follow the same pattern and deploy ql.io on your own closer to your applications.
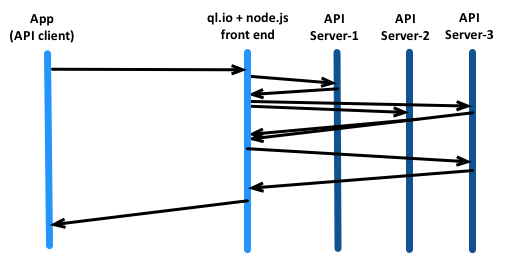
Deploying on the front end
Our choice of Javascript and node.js for building ql.io provides an additional deployment option: front-end applications built on node.js can use ql.io programmatically.
Why node.js
Early on, one of the critical choices that we had to make was the software stack. We had two choices: Should we go with the proven Java stack that has full operational support within eBay? Or should we choose a stack like node.js with its excellent support for async I/O, but which was not yet proven when we started the project? Moreover, very few companies had operational experience with node.js. This was not an easy choice to make. In our deliberations, we considered the following systemic qualities, in their order of importance:
- Performance and scalability for I/O workloads. Of workloads performed during script execution, a significant percentage is I/O bound. CPU loads are limited to in-memory tasks like joining and projections. Blocking I/O was out of the equation for supporting such workloads.
- Operability. We need to be able to monitor the runtime, know what is going on, and react quickly when things go wrong. Furthermore, integrating with eBay’s logging and monitoring tools is a prerequisite for bringing in a new technology stack.
- Low per-connection memory overhead. Since script execution involves some slow and some fast APIs, we need the stack to remain stable as the number of open connections increases.
- Dynamic language support. This consideration had two parts. We wanted to build ql.io very quickly in a very small team with low code-to-execution turn-around times. This approach helps us iterate rapidly in the face of bugs as well as new use cases. In addition, we wanted application developers to be able to extend ql.io’s processing pipeline with small snippets of code.
After some analysis and prototyping, we chose Javascript as the language and node.js as the runtime stack. Here are some highlights of our experience so far:
- Javascript and node.js allowed us to iterate very rapidly. Though we were initially concerned about finding the right tools and libraries, the node.js ecosystem proved sufficient for us to build as complex a system as ql.io.
- We were able to tune a regular developer-quality Ubuntu workstation to handle more than 120,000 active connections per node.js process, with each connection consuming about 2k memory. We knew we could go further with the number of connections; although we did not spend the time to go beyond, this gave us the confidence to proceed with node.js.
- ql.io’s core engine does automatic fork-join of HTTP requests by using compile-time analysis of scripts. Node’s evented I/O model freed us from worrying about locking and concurrency issues that are common with multithreaded async I/O.
- We did pay some operationalization tax while we prepared the ql.io and node.js stack for integration with eBay’s monitoring and logging systems. This was a one-time penalty.
What’s next
We’re not done with ql.io yet, and we want to continue to develop ql.io in the open. Go to ql.io on Github and http://ql.io to find more about ql.io, try it out, discuss it, and participate.