We are very excited to announce that eBay has released to the open-source community our distributed analytics engine: Kylin (http://kylin.io). Designed to accelerate analytics on Hadoop and allow the use of SQL-compatible tools, Kylin provides a SQL interface and multi-dimensional analysis (OLAP) on Hadoop to support extremely large datasets.
Kylin is currently used in production by various business units at eBay. In addition to open-sourcing Kylin, we are proposing Kylin as an Apache Incubator project.
Background
The challenge faced at eBay is that our data volume has become bigger while our user base has become more diverse. Our users – for example, in analytics and business units – consistently ask for minimal latency but want to continue using their favorite tools, such as Tableau and Excel.
So, we worked closely with our internal analytics community and outlined requirements for a successful product at eBay:
- Sub-second query latency on billions of rows
- ANSI-standard SQL availability for those using SQL-compatible tools
- Full OLAP capability to offer advanced functionality
- Support for high cardinality and very large dimensions
- High concurrency for thousands of users
- Distributed and scale-out architecture for analysis in the TB to PB size range
We quickly realized nothing met our exact requirements externally – especially in the open-source Hadoop community. To meet our emergent business needs, we decided to build a platform from scratch. With an excellent team and several pilot customers, we have been able to bring the Kylin platform into production as well as open-source it.
Feature highlights
Kylin is a platform offering the following features for big data analytics:
- Extremely fast OLAP engine at scale: Kylin is designed to reduce query latency on Hadoop for 10+ billion rows of data.
- ANSI SQL on Hadoop: Kylin supports most ANSI SQL query functions in its ANSI SQL on Hadoop interface.
- Interactive query capability: Users can interact with Hadoop data via Kylin at sub-second latency – better than Hive queries for the same dataset.
- MOLAP cube query serving on billions of rows: Users can define a data model and pre-build in Kylin with more than 10+ billions of raw data records.
- Seamless integration with BI Tools: Kylin currently offers integration with business intelligence tools such as Tableau and third-party applications.
- Open-source ODBC driver: Kylin’s ODBC driver is built from scratch and works very well with Tableau. We have open-sourced the driver to the community as well.
- Other highlights:
- Job management and monitoring
- Compression and encoding to reduce storage
- Incremental refresh of cubes
- Leveraging of the HBase coprocessor for query latency
- Approximate query capability for distinct counts (HyperLogLog)
- Easy-to-use Web interface to manage, build, monitor, and query cubes
- Security capability to set ACL at the cube/project level
- Support for LDAP integration
The fundamental idea
The idea of Kylin is not brand new. Many technologies over the past 30 years have used the same theory to accelerate analytics. These technologies include methods to store pre-calculated results to serve analysis queries, generate each level’s cuboids with all possible combinations of dimensions, and calculate all metrics at different levels.
For reference, here is the cuboid topology:
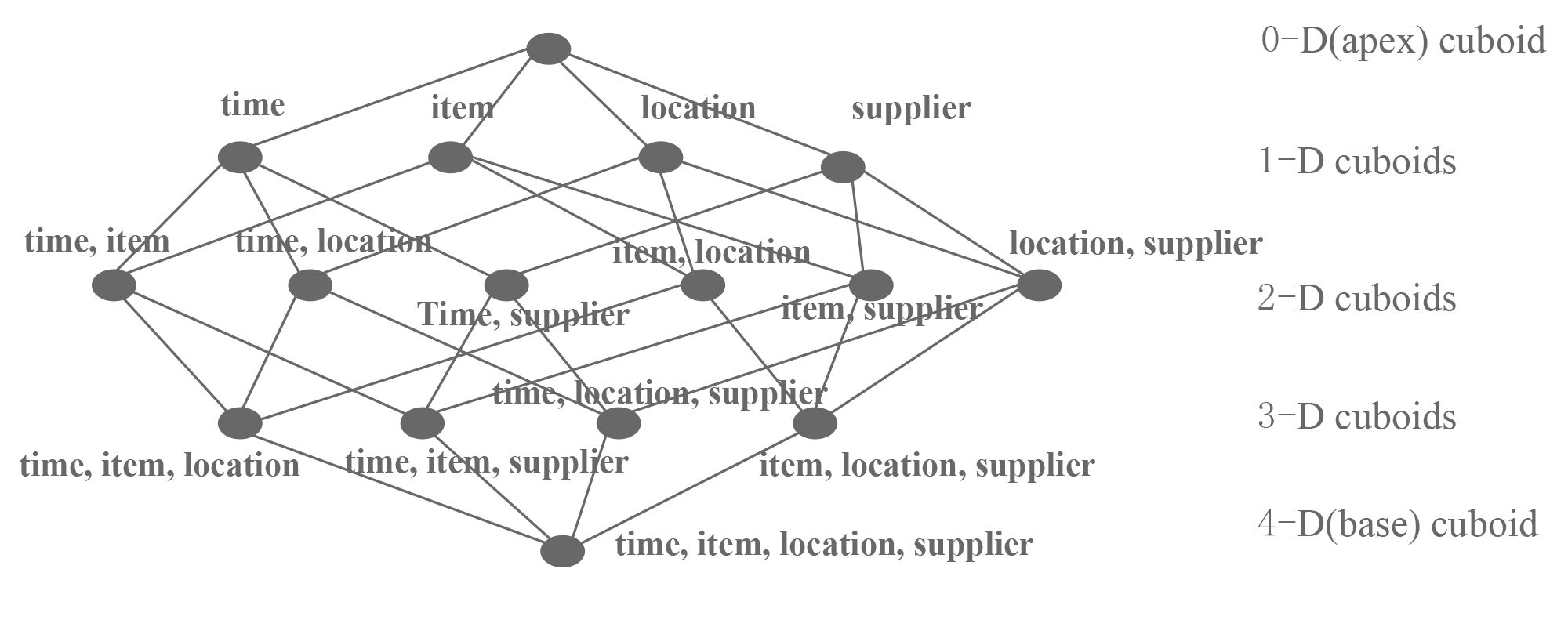
When data becomes bigger, the pre-calculation processing becomes impossible – even with powerful hardware. However, with the benefit of Hadoop’s distributed computing power, calculation jobs can leverage hundreds of thousands of nodes. This allows Kylin to perform these calculations in parallel and merge the final result, thereby significantly reducing the processing time.
From relational to key-value
As an example, suppose there are several records stored in Hive tables that represent a relational structure. When the data volume grows very large – 10+ or even 100+ billions of rows – a question like “how many units were sold in the technology category in 2010 on the US site?” will produce a query with a large table scan and a long delay to get the answer. Since the values are fixed every time the query is run, it makes sense to calculate and store those values for further usage. This technique is called Relational to Key-Value (K-V) processing. The process will generate all of the dimension combinations and measured values shown in the example below, at the right side of the diagram. The middle columns of the diagram, from left to right, show how data is calculated by leveraging MapReduce for the large-volume data processing.

Kylin is based on this theory and is leveraging the Hadoop ecosystem to do the job for huge volumes of data:
- Read data from Hive (which is stored on HDFS)
- Run MapReduce jobs to pre-calculate
- Store cube data in HBase
- Leverage Zookeeper for job coordination
Architecture
The following diagram shows the high-level architecture of Kylin.

This diagram illustrates how relational data becomes key-value data through the Cube Build Engine offline process. The yellow lines also illustrate the online analysis data flow. The data requests can originate from SQL submitted using a SQL-based tool, or even using third-party applications via Kylin’s RESTful services. The RESTful services call the Query Engine, which determines if the target dataset exists. If so, the engine directly accesses the target data and returns the result with sub-second latency. Otherwise, the engine is designed to route non-matching dataset queries to SQL on Hadoop, enabled on a Hadoop cluster such as Hive.
Following are descriptions of all of the components the Kylin platform includes.
- Metadata Manager: Kylin is a metadata-driven application. The Metadata Manager is the key component that manages all metadata stored in Kylin, including the most important cube metadata. All other components rely on the Metadata Manager.
- Job Engine: This engine is designed to handle all of the offline jobs including shell script, Java API, and MapReduce jobs. The Job Engine manages and coordinates all of the jobs in Kylin to make sure each job executes and handles failures.
- Storage Engine: This engine manages the underlying storage – specifically the cuboids, which are stored as key-value pairs. The Storage Engine uses HBase – the best solution from the Hadoop ecosystem for leveraging an existing K-V system. Kylin can also be extended to support other K-V systems, such as Redis.
- REST Server: The REST Server is an entry point for applications to develop against Kylin. Applications can submit queries, get results, trigger cube build jobs, get metadata, get user privileges, and so on.
- ODBC Driver: To support third-party tools and applications – such as Tableau – we have built and open-sourced an ODBC Driver. The goal is to make it easy for users to onboard.
- Query Engine: Once the cube is ready, the Query Engine can receive and parse user queries. It then interacts with other components to return the results to the user.
In Kylin, we are leveraging an open-source dynamic data management framework called Apache Calcite to parse SQL and plug in our code. The Calcite architecture is illustrated below. (Calcite was previously called Optiq, which was written by Julian Hyde and is now an Apache Incubator project.)

Kylin usage at eBay
At the time of open-sourcing Kylin, we already had several eBay business units using it in production. Our largest use case is the analysis of 12+ billion source records generating 14+ TB cubes. Its 90% query latency is less than 5 seconds. Now, our use cases target analysts and business users, who can access analytics and get results through the Tableau dashboard very easily – no more Hive query, shell command, and so on.
What’s next
- Support TopN on high-cardinality dimension: The current MOLAP technology is not perfect when it comes to querying on a high-cardinality dimension – such as TopN on millions of distinct values in one column. Similar to search engines (as many researchers have pointed out), the inverted index is the reasonable mechanism to use to pre-build such results.
- Support Hybrid OLAP (HOLAP): MOLAP is great to serve queries on historical data, but as more and more data needs to be processed in real time, there is a growing requirement to combine real-time/near-real-time and historical results for business decisions. Many in-memory technologies already work on Relational OLAP (ROLAP) to offer such capability. Kylin’s next generation will be a Hybrid OLAP (HOLAP) to combine MOLAP and ROLAP together and offer a single entry point for front-end queries.
Open source
Kylin has already been open-sourced to the community. To develop and grow an even stronger ecosystem around Kylin, we are currently working on proposing Kylin as an Apache Incubator project. With distinguished sponsors from the Hadoop developer community supporting Kylin, such as Owen O’Malley (Hortonworks co-founder and Apache member) and Julian Hyde (original author of Apache Calcite, also with Hortonworks), we believe that the greater open-source community can take Kylin to the next level.
We welcome everyone to contribute to Kylin. Please visit the Kylin web site for more details: http://kylin.io.
To begin with, we are looking for open-source contributions not only in the core code base, but also in the following areas:
- Shell Client
- RPC Server
- Job Scheduler
- Tools
For more details and to discuss these topics further, please follow us on twitter @KylinOLAP and join our Google group: https://groups.google.com/forum/#!forum/kylin-olap
Summary
Kylin has been deployed in production at eBay and is processing extremely large datasets. The platform has demonstrated great performance benefits and has proved to be a better way for analysts to leverage data on Hadoop with a more convenient approach using their favorite tool. We are pleased to open-source Kylin. We welcome feedback and suggestions, and we look forward to the involvement of the open-source community.
Editor's Note: The eBay Inc. Kylin Team contributed to this article.